
참고자료 ➡️ https://www.boostcourse.org/ai111/lecture/1108319
딥러닝 기초 다지기
부스트코스 무료 강의
www.boostcourse.org





1. 가설(Hypothesis)과 비용 함수(Cost Function)
- 가설 H(x) : 가설은 주어진 입력 xx에 대해 모델이 예측하는 출력 값을 나타냄.
- 가설 함수 H(x)는 우리가 데이터에서 학습한 모델이며, 목표는 이 가설이 실제 값에 최대한 가깝도록 만드는 것.
- 일반적으로 가설은 다음과 같은 선형 방정식으로 표현됨.
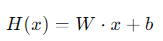
여기서 W는 가중치, b는 편향(bias)
- 비용 함수(Cost Function) : 비용 함수는 가설 H(x)와 실제 값 y 간의 차이를 측정하는 함수.
- 비용 함수의 목적은 이 차이를 최소화하는 것.
- 일반적으로 사용되는 비용 함수는 평균 제곱 오차(Mean Squared Error, MSE)

2. 경사하강법(Gradient Descent)
- 개념 : 경사하강법은 비용 함수를 최소화하는 가중치 W와 편향 를 찾기 위한 최적화 알고리즘.
- 비용 함수의 기울기(미분값)를 계산하여, 이 기울기가 가장 작은 방향으로 조금씩 이동하면서 최적의 파라미터를 찾아감.
- 경사하강법 알고리즘 :
- 초기화 : W와 b를 무작위로 초기화.
- 기울기 계산 : 비용 함수 J(W,b)의 기울기(Gradient)를 계산.
- 업데이트 : W와 를 기울기를 따라 이동시키며 업데이트.
- 반복: 기울기가 거의 0에 가까워질 때까지 위의 과정을 반복.

여기서 α는 학습률(Learning Rate)로, 얼마나 크게 이동할지를 결정.
- 미분과 기울기 : 비용 함수의 기울기를 구하기 위해 미분을 사용.

- 이 미분 값을 이용하여 가중치와 편향을 업데이트.
- 만약 미분한 값이 양수라면 W의 값이 줄어들고, 음수라면 W의 값이 증가.

3. 언더피팅(Underfitting)과 오버피팅(Overfitting)
- 언더피팅 : 모델이 너무 단순하여 데이터의 패턴을 잘 학습하지 못하는 경우.
- 비용 함수가 충분히 낮아지지 않고, 데이터의 중요한 특징을 포착하지 못해 발생.
- 주로 높은 편향(Bias)을 가진 모델에서 발생.
- 해결법 : 모델의 복잡도를 높이거나, 더 많은 특징(Feature)을 추가, 학습 시간을 늘리기.
- 오버피팅 : 모델이 너무 복잡하여 학습 데이터에 지나치게 맞추는 경우.
- 비용 함수는 학습 데이터에서 낮지만, 새로운 데이터에서는 성능이 좋지 않음.
- 주로 높은 분산(Variance)을 가진 모델에서 발생.
- 해결법 : 정규화(Regularization) 기법 사용, 데이터의 양을 늘리기, 조기 종료(Early Stopping) 사용.
4. 교차 검증(Cross Validation)
- 개념 : 모델의 성능을 평가하기 위해 데이터를 여러 번 나누어 학습과 평가를 반복하는 방법.
- 데이터셋이 작을 때 모델의 일반화 성능을 평가하는 데 유용.
- K-겹 교차 검증(K-Fold Cross Validation) : 데이터를 K개의 폴드(Fold)로 나누고, K번 학습과 검증을 반복하여 평균 성능을 평가. 각 폴드가 한 번씩 검증 데이터셋이 되며, 최종 성능은 K번의 검증 결과의 평균으로 평가.
5. 편향-분산 상충(Bias-Variance Tradeoff)
- 개념 : 모델의 복잡도에 따라 편향과 분산 사이에서 균형을 맞추는 문제. 복잡한 모델은 분산이 높고 편향이 낮아지며, 단순한 모델은 편향이 높고 분산이 낮아짐.
6. 부트스트래핑(Bootstrapping)
- 개념 : 주어진 데이터셋에서 복원 추출을 통해 여러 개의 새로운 데이터셋을 만드는 방법.
- 이 방법을 통해 모델의 불확실성을 평가하거나, 다양한 학습을 통해 모델 성능을 향상시킬 수 있음.
- 사용 사례 : 앙상블 학습 기법(Bagging, Random Forest)에서 사용.
7. 배깅(Bagging)
- 개념 : 부트스트래핑으로 생성된 여러 데이터셋으로 각각 모델을 학습시키고, 그 결과를 평균내거나 투표하여 최종 예측을 만드는 앙상블 학습 방법. 분산을 줄여 오버피팅을 방지하는 데 효과적.
- 대표적인 예 : 랜덤 포레스트(Random Forest)
8. 부스팅(Boosting)
- 개념 : Weak Learner를 순차적으로 학습시켜 Strong Learner를 만드는 방법. 이전 모델이 틀린 데이터를 다음 모델이 더 잘 맞추도록 가중치를 부여해 학습을 진행.

- 대표적인 예 : AdaBoost, Gradient Boosting
728x90
반응형
'딥러닝' 카테고리의 다른 글
| Sigmoid & Softmax (feat.One-hot encoding) (0) | 2024.09.12 |
|---|---|
| Neural Network & MLP 개념 정리 (0) | 2024.08.22 |
| U-Net과 Transformer 비교 + 관련 개념 정리 (0) | 2024.07.30 |
| Neural Networks - MLP (0) | 2024.07.28 |
| 딥러닝 Historical Review - 고려대학교 최성준 교수님 (0) | 2024.04.11 |



